Book Notes: DevOps Handbook, The
August 27, 2023
#book-notes#devops#automation#testing#continuous-integration#continuous-deployment#cicd#infrastructure#infrastructure-as-code#git#feedback-loops#continuous-learning

Here are some point-form takeaways from my notes from reading The DevOps Handbook by John Willis, Gene Kim, and Patrick Debois.
Index
Core premise First way of DevOps: Flow
- Make work visible
- Limit WIP
- Small batch sizes
- Elevate constraints in value streams
- Categories of waste and hardship
- Developer productivity vs number of developers Second way of DevOps: Feedback Third way of DevOps: Continuous Learning and Experimentation Practices to improve the three ways
- Immutable infrastructure
- Infrastructure as code
- Testing pyramid
- Continuous integration
- No more pull requests
- Git strategies
- Continuous delivery
- Metrics
- A/B testing
- Chatbots for automation
- Single company-wide repository
Core premise
At the core of this book are the three "ways of DevOps".
- Left-to-right flow of work from development to operations to the customer.
- Speeding up this channel gets work from idea to the customer faster.
- Decreasing lead times through better process leads to higher value delivered to customers and higher developer satisfaction.
- Resulting practices from improving this channel include continuous integration, continuous deployment, and infrastructure-as-code, among others.
- Right-to-left constant feedback from customers to operations to developers.
- Prevent problems from happening again.
- Enable faster detection of and recovery from issues.
- Resulting practices from improving this channel are easy to access and understand metrics, and making your systems more observable.
- Cycles of learning. Creating a generative, high-trust culture.
- Scientific approach to risk taking.
- Organizational learning. Multiply the effects of new knowledge. Transform local discoveries into global improvements.
- Amplifying positive feedback loops creating ever-safer systems.
First way of DevOps: Flow
Make work visible
Make work visible. Kanban boards allow you to easily see the state of a current projects and the team in general. Keep work from development and operations on the same kanban board so that both teams can see the in-progress work of the other.
Limit WIP
Multi-tasking significantly degrades efficiency. Limit the number of WIP items to keep teams focused. You can do this by controlling the swim lane size in your kanban boards.
Reference: Making Work Visible: Exposing Time Theft to Optimize Work & Flow by Dominica Degrandis
Small batch sizes
Small batch sizes lead to faster lead times for individual projects, less WIP, faster detection of issues, and less rework.
Elevate constraints in value streams
Focus efforts on optimizing bottlenecks in your value streams. The most value and effect can be had by remediating bottlenecks rather than steps before or after a bottleneck.
Categories of waste and hardship
These categories of work are where inefficiencies are introduced and time and effort are wasted.
- Partially done work: WIP, work waiting in queues, etc. Partially done work loses value as time passes.
- Extra processes: Additional work that doesn't add value to the customer. Increases lead time.
- Extra features: Output that is not valued by the customer. Adds complexity and increases lead time.
- Task switching: Multitasking adds effort and time to the value stream.
- Waiting: Delays or queues increase lead time.
- Motion: Friction in handoffs adds ambiguity into the value stream and can increase lead time.
- Defects: Bugs, miscommunications, etc. add lead time and rework.
Reference: Implementing Lean Software Development: From Concept to Cash by Mary Poppendieck and Tom Poppendieck
Added categories from Damon Edwards:
- Nonstandard or manual work: Any manual work that can be automated. Increases lead time and can lead to human error.
- Heroics: Individuals and teams should never be put in positions where they must perform unreasonable acts. Don't let heroics become the norm. When an team member needs to perform heroics, a breakdown of process has occurred. Should be remedied such that it's never required again.
Developer productivity vs number of developers
When we increase the number of developers, individual developer productivity often significantly decreases due to communication, integration, and testing overhead
Second way of DevOps: Feedback
Feedback and feedforward loops allow us to detect and remediate problems while they're smaller, cheaper, and easier to fix, to avert problems before they cause a catastrophe, and create organizational learning that we integrate into future work.
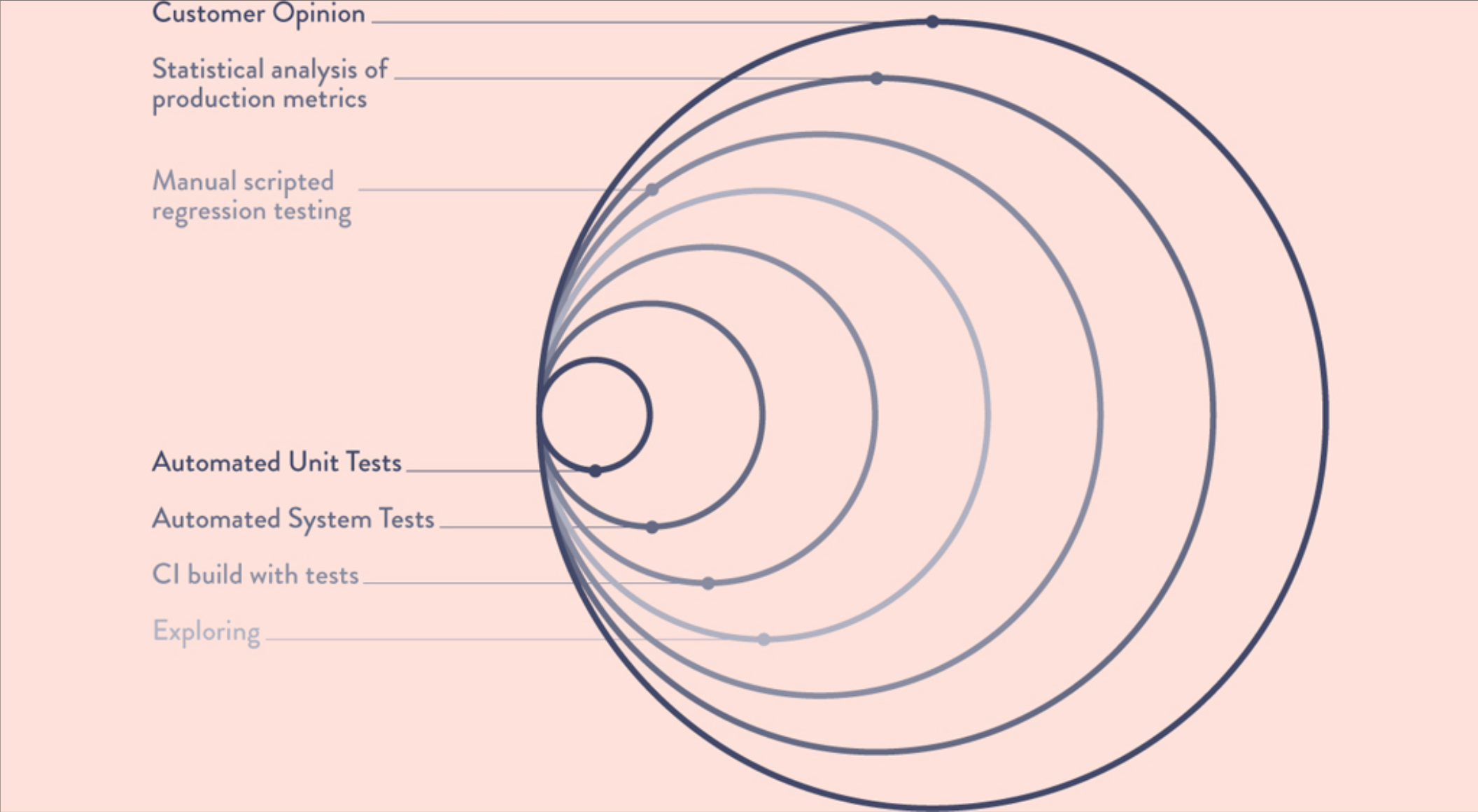 ^ Time it takes to get feedback from different stages of feedback. Taken from DevOps Handbook
^ Time it takes to get feedback from different stages of feedback. Taken from DevOps Handbook
Third way of DevOps: Continuous Learning and Experimentation
Couple of quotes:
When accidents and failures occur, instead of looking for human error, we look for how we can redesign the system to prevent the accident from happening again.
^ DevOps Handbook
Even more important than daily work is the improvement of daily work.
^ Mike Orzen, author of Lean IT
You want to create an environment of trust where experimentation and learning are the norm. You want to have simple process in place to elevate local learnings to global company-wide knowledge.
Practices to improve the three ways
Immutable infrastructure
Never allow changes directly to infrastructure. Any changes must be checked into version control in our infrastructure-as-code, then deployed as new infrastructure that replaces the existing infrastructure, rather than tweaking it in-place.
You wouldn't let someone log into app servers and make changes directly to the code. So why let that happen for infrastructure?
Infrastructure as code
- Version control for your infrastructure. Blame and change history.
- Single source of truth for the state of your infrastructure.
- Replicate environments in a quick, repeatable, documented way.
- Make environments easier to rebuild than repair, makes it simpler and quicker to resolve issues.
Testing pyramid
Should be able to discover the majority of issues in the quickest running tests, to facilitate fast feedback and iteration.

If an issue is found during integration or end-to-end testing, which usually take a long time to run, a unit test should be created that catches this issue. That way if the same issue happens again, it will be caught sooner and the developer can get faster feedback.
Not only should you improve your code coverage over time, you should aim to move tests down the pyramid so that issues continue to be found faster.
Manual tests can be run in parallel with automated tests (which also could be running in parallel with each other) to improve testing efficiency.
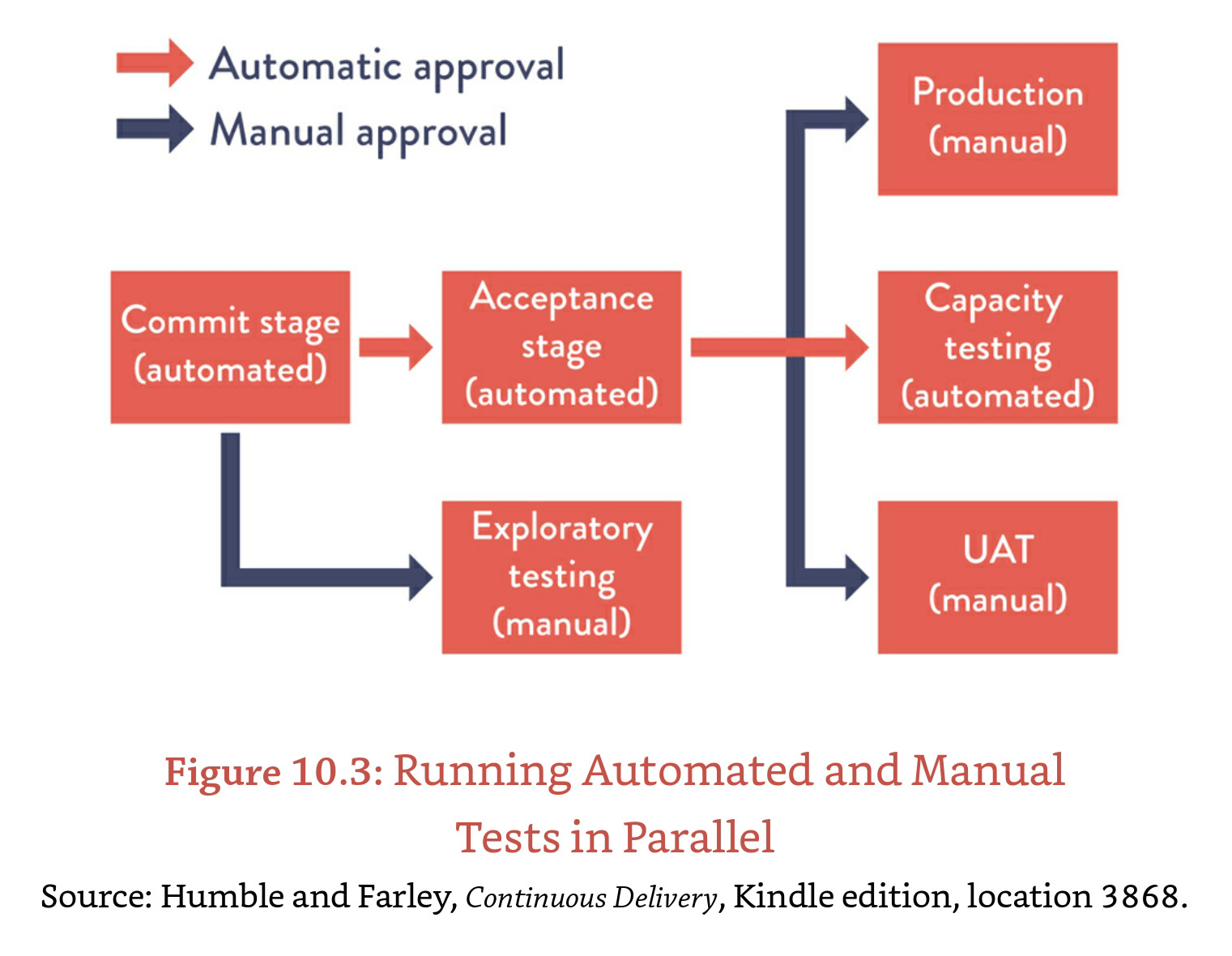
Continuous integration
The purpose of creating and working in branches is so that multiple developers can work in parallel and minimize conflicts.
Developers then need to manually "integrate" their code with other work. This process can be error prone. Especially when you don't understand someone else's code that is causing a conflict. This issue is exasperated the more developers are working in parallel.
Continuous Integration solves this problem by getting everyone to integrate into the main branch daily as part of their normal work.
No more pull requests
Pull requests were designed by GitHub to facilitate accepting contributions from unknown and untrusted developers on open source projects. They give maintainers an opportunity to confirm the code matches the style and ethos of the project.
Developers within an organization should already share the style and ethos of the team. They should be trusted to continue to promote that ethos in their code.
Pull requests sacrifice performance and quality. This is a worth while tradeoff for open source projects. They force the author to wait for review, causing their work to become stale. And they force reviewers to context switch to review code. Often they don't take the time necessary to actually understand the code because of time pressures, so errors slip though anyway even though all that time was spent!
Using pull request internally is like forcing your family through airport security just to enter your house. It's a costly solution to a different problem.
If your worry is having multiple pairs of eyes on the code before it's deployed, that should happen way earlier in the project, before hard to change decisions are solidified. For example, having multiple devs on a project, Pari programming, frequent code reviews, etc. These can replace pull requests and assist in automating the integration and deployment pipeline.
Related reference not from DevOps Handbook: Pull Requests from Infrastructure as Code by Kief Morris
Git strategies
Optimizing for individual productivity: individual branches. Quick progress in the beginning, but offload integration work to the end, or sporadically through the project. This is more like waterfall development.
Optimizing for team productivity: always integrating and working off of main. Main is always up to date with the latest work and in a deployable state. This is more like agile development.
When merging is difficult because of large batch sizes, developers become incentivized not to refactor code so that they keep their integration simple. This contributes to tech debt in the codebase growing over time.
Continuous delivery
Any code that passes all tests, builds, and is deployable in a production-like environment will be automatically deployed to production.
Our code and environments should be designed and built in such a way that the release of new functionality to users does not require a change to our application code. We should decouple the ideas of releasing features to users and deploying code to an environment. They are two different acts serving two different stakeholders.
When we're deploying code all the time through continuous deployment and dark launching, releasing new functionality to users becomes simply a business and marketing decision.
Reference: Continuous Delivery: Reliable Software Releases Through Build, Test, and Deployment Automation. by Jez Humble and David Farley
Metrics
We should enable every developer to create metrics in their daily work and be able to display and analyze them.
Metrics should be visible and digestible for anyone in the company, and perhaps even publicly.
A/B testing
If you don't have data about how whether a feature or change is performing compared to a baseline, then you don't know if the change has zero impact or even negative impact.
A study at Microsoft showed that through AB testing, 2/3 of proposed changed showed zero or negative impact.
Reference: Release It!: Design and Deploy Production-Ready Software by Michael T. Nygard
Chatbots for automation
Example:
@hubot deploy owl to production
The results of chatbot commands are returned to the chat.
- Everyone can see everything that is happening
- Engineers, on their first day of work, can see what daily work looked like and how it was performed
- People were more apt to ask for help when they saw others helping each other
- Rapid organizational learning was enabled and accumulated
Single company-wide repository
Everyone has access to all the most up to date code easily.
Randy Shoup described the single repository as the most powerful mechanism for preventing failures at Google.
Tom Limoncelli described it as a competitive advantage for Google.